Charts I Created
I generated each of these charts using Python after full data cleaning and feature engineering. Click any chart to expand it.
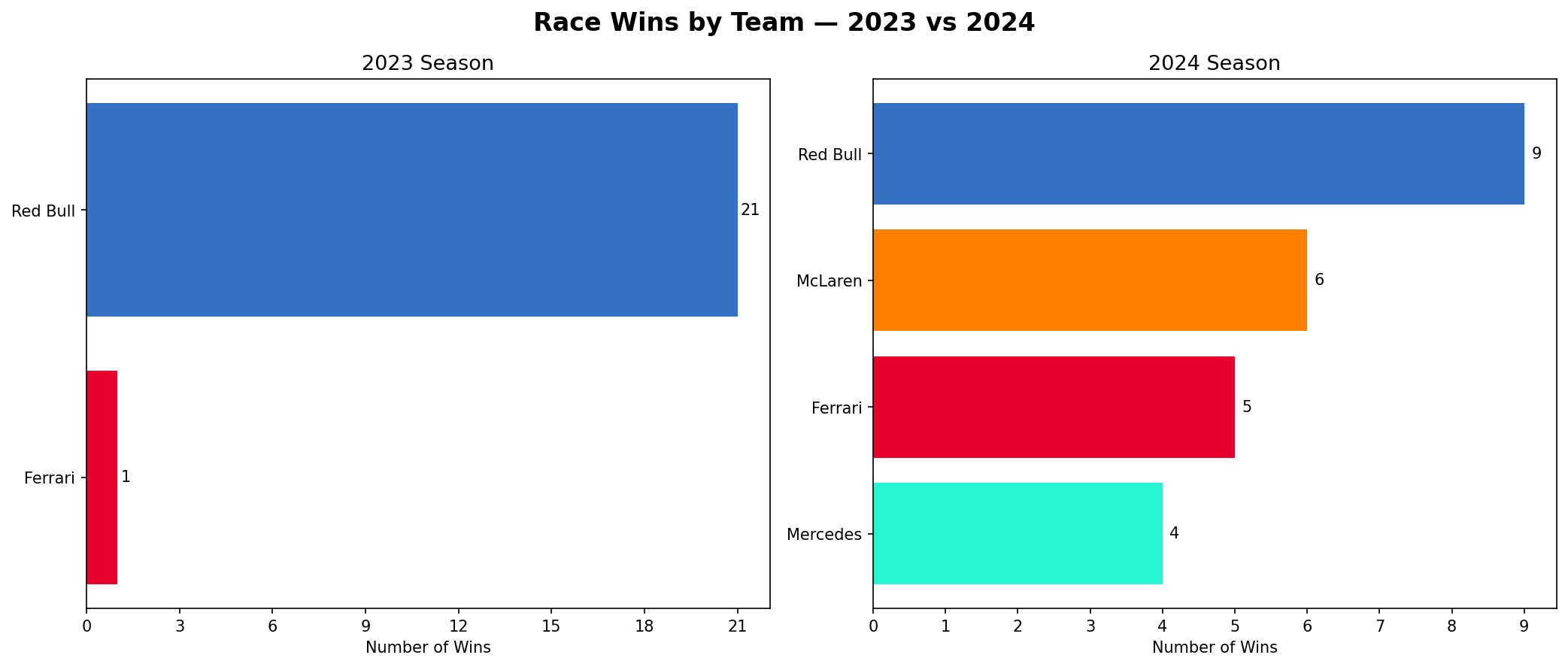
Race Wins by Team — 2023 vs 2024
This is the most direct summary of what changed. One bar chart tells you everything about the 2023 season, and one tells you everything about 2024. In 2023 Red Bull won 21 of 22 races. In 2024 the wins got split across Red Bull, McLaren, Ferrari, and Mercedes. This showed that competitive balance was starting to return in F1.
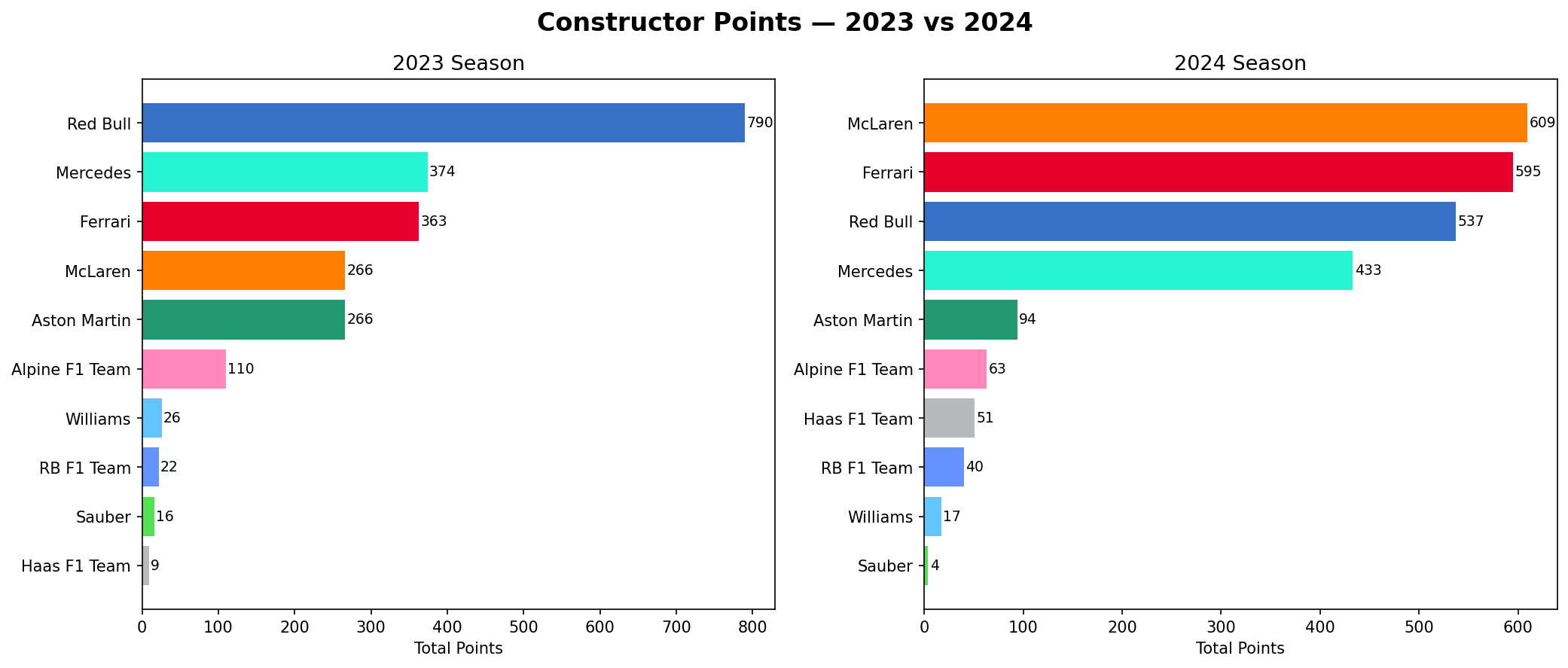
Constructor Championship Points
The main thing that matters in F1 is points. This shows the actual championship scoring gap between Red Bull and the rest of the field across both seasons. Red Bull scored 790 points in 2023 — more than double of Mercedes who were in 2nd place. In 2024 they finished 3rd with 537, behind McLaren (609) and Ferrari (595).
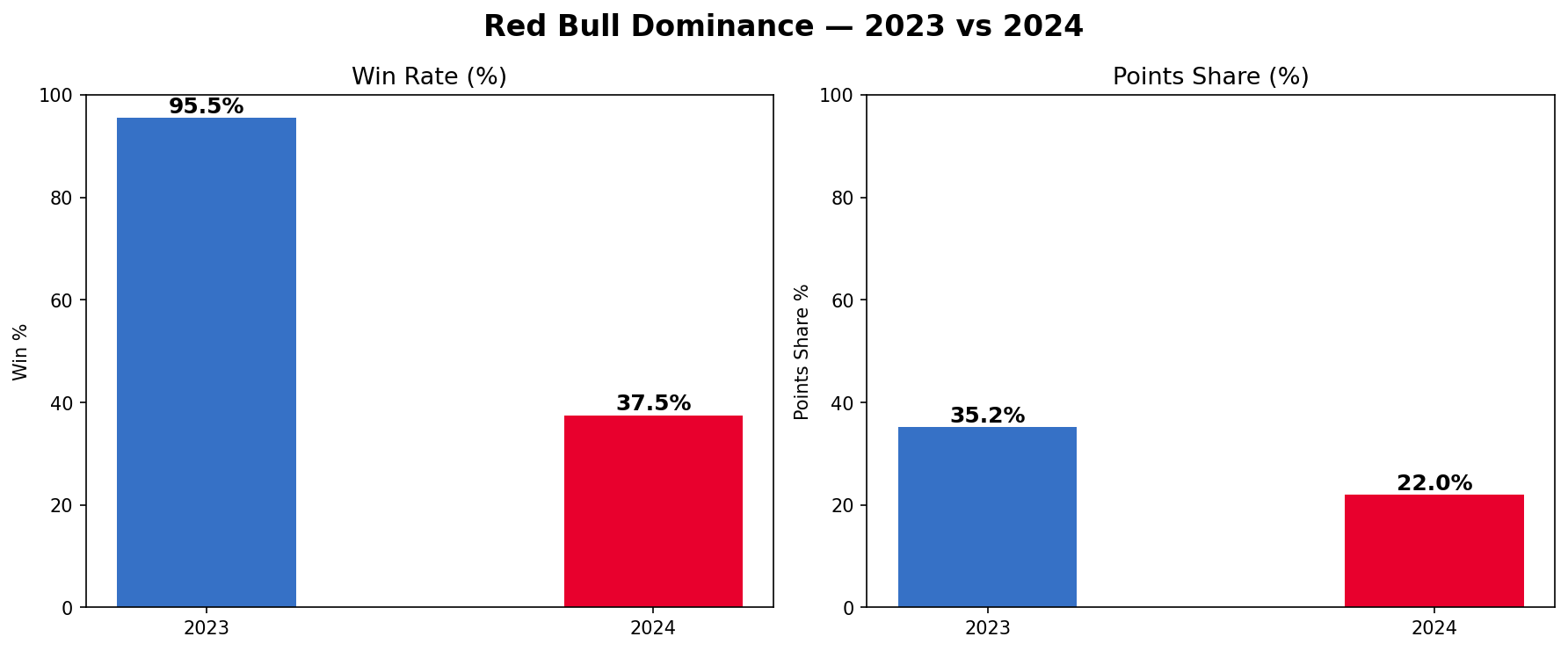
Red Bull Dominance Metrics
There are 2 metrics that can draw a very clear picture of the whole situation here — the percentage of races won by Red Bull, and the percentage of all points scored by every team combined that Red Bull actually scored. Win rate dropped from 95.5% to 37.5%. Points share of the entire field dropped from 35.2% to 22%. This quantifies the sheer scale of the competitive swing.
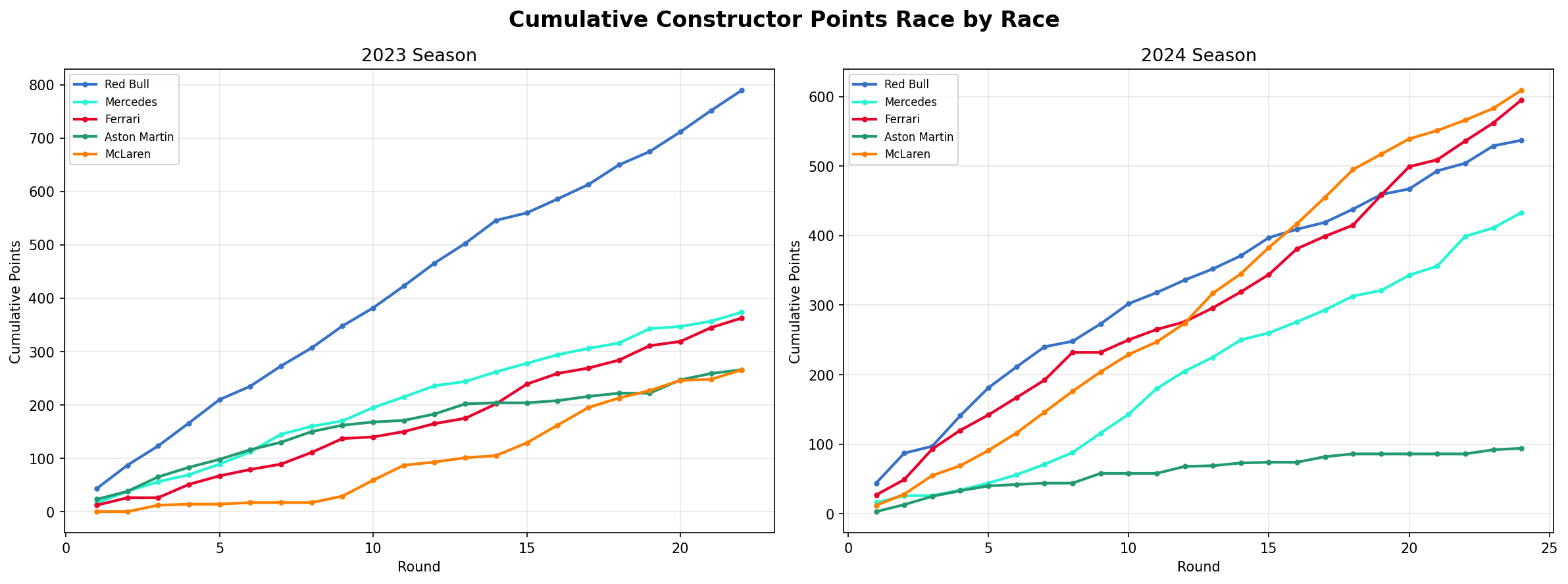
Cumulative Constructor Points — Race by Race
Instead of a single total, this plot tracks how points accumulated race by race — so you can see exactly when Red Bull pulled away in 2023 and exactly how differently the 2024 season unfolded. In 2023 Red Bull's line shoots away from the field almost immediately. But in 2024 the top 4 teams track closely together for the entire season.
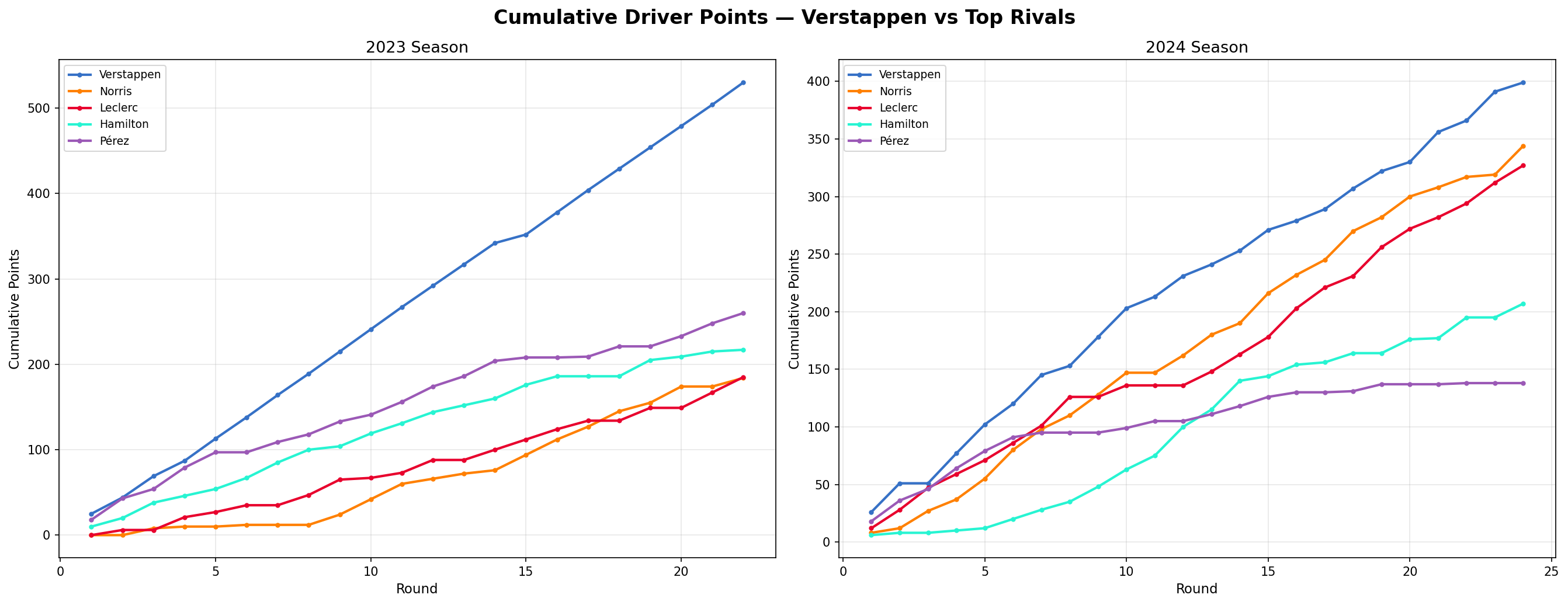
Driver Championship Battle
This one is a bit of a personal comparison between Max Verstappen and his closest rivals, round by round, across both seasons. Verstappen's 2023 lead kept increasing relentlessly. But in 2024 Norris and Leclerc stayed within striking distance for much longer before Verstappen finally got ahead.
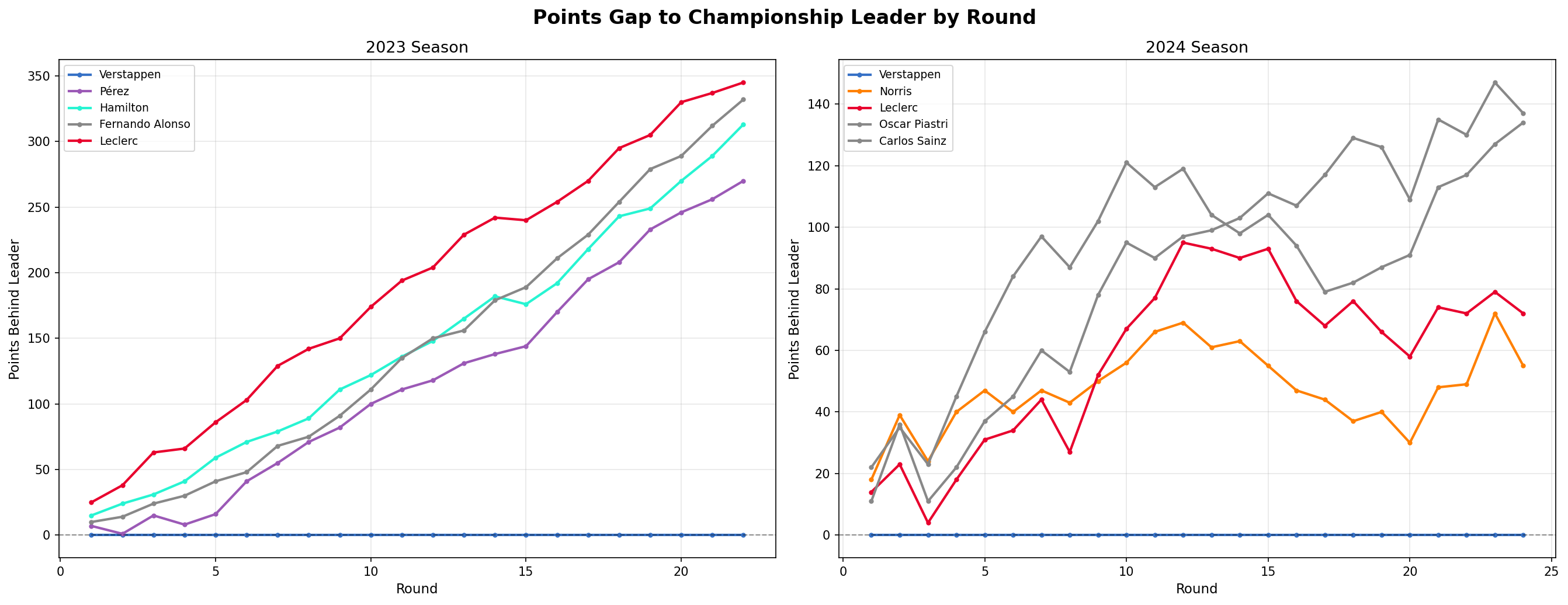
Points Gap to Championship Leader
This is kind of the opposite of Chart 5. Instead of showing total points, this shows how far behind the leader each driver was after every round. The steeper the drop, the more dominant the leader. The gap curves downward steeply in 2023 but in 2024 competitors stay comparatively nearer to 0 throughout.
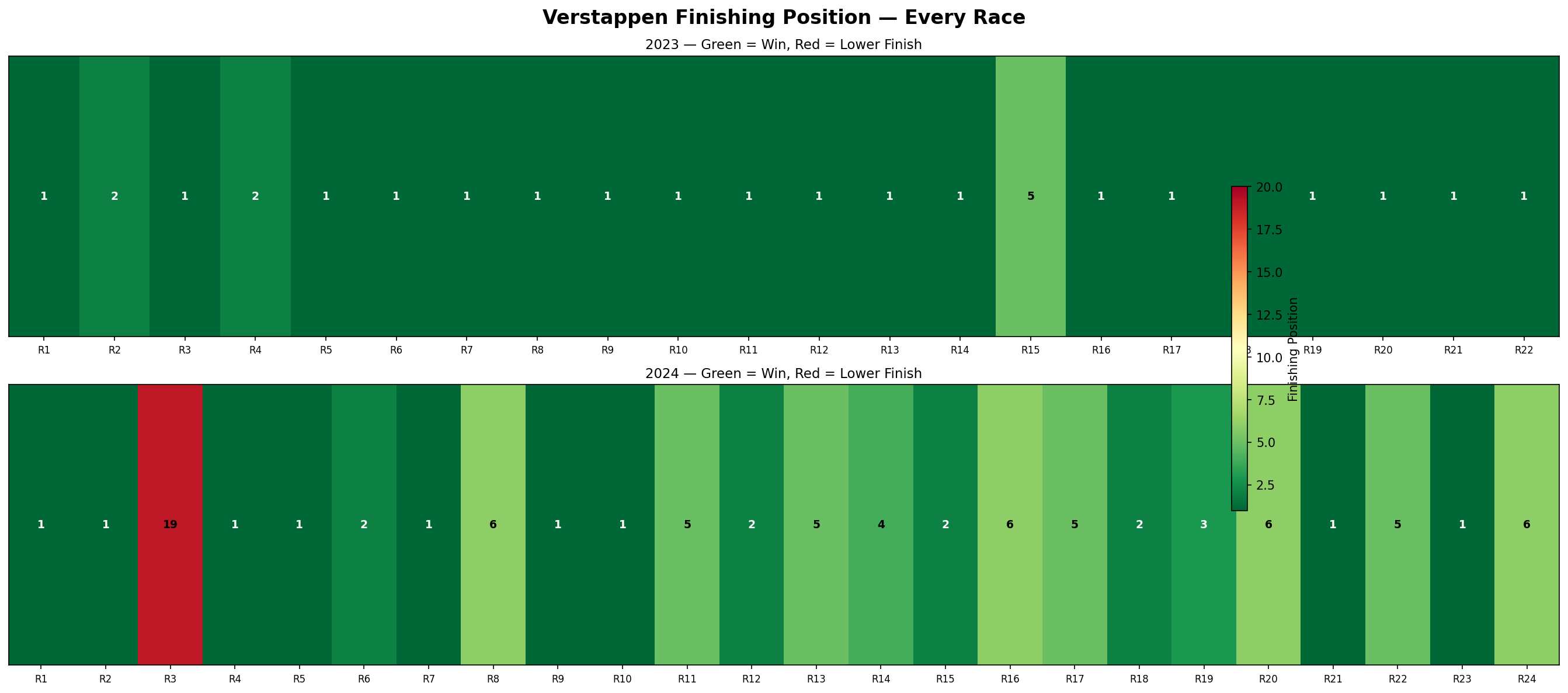
Verstappen Finishing Position Heatmap
Here every box is one race of Verstappen. Green means he won or finished on the podium. Red means a bad result. It basically summarizes his whole 2023 and 2024 seasons. 2023 is almost entirely green. But 2024 shows more variation, including a DNF and several P4-P6 finishes.
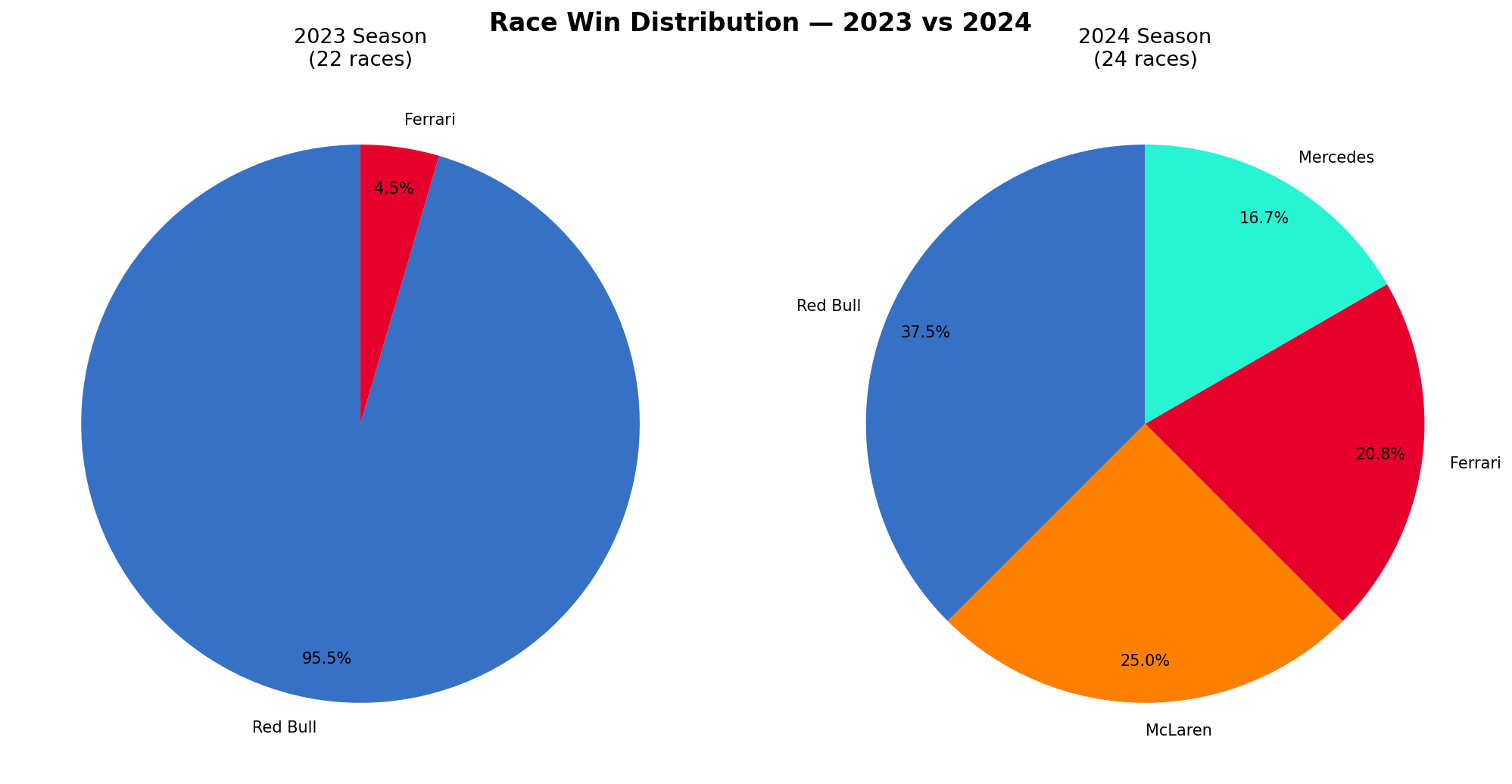
Race Win Distribution
This is probably the simplest chart in the project but also the most powerful one. The 2023 chart is almost completely Red Bull with a tiny Ferrari slice. The 2024 chart is split 4 ways. This simple visual is enough to tell the whole story of F1's shift.
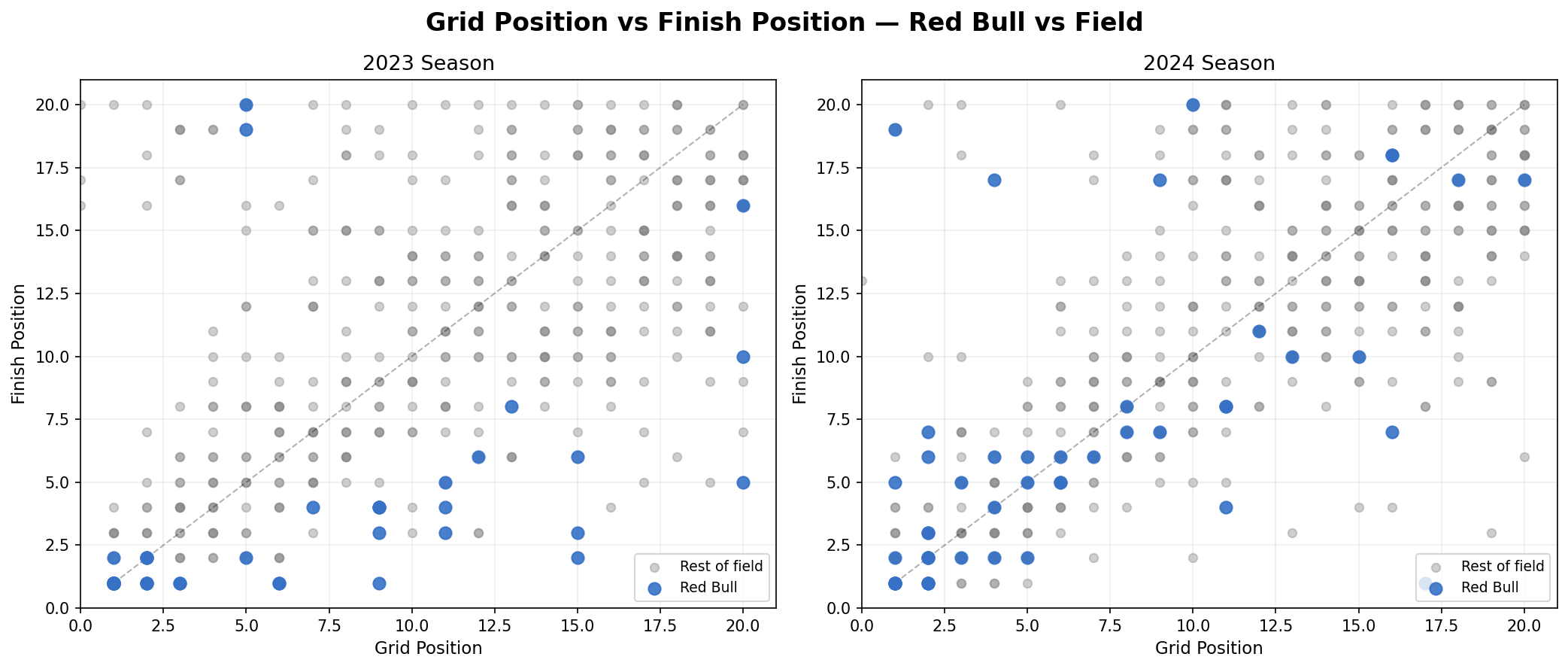
Grid Position vs Finish Position
This compares where Red Bull started each race versus where they finished — plotted against the rest of the field. In 2023 those blue dots are in a completely different corner of the chart from everyone else. Blue dots (Red Bull) are isolated in the bottom and mostly in the left in 2023 which means they always qualified and finished at the front. In 2024 they start mixing into the gray field.
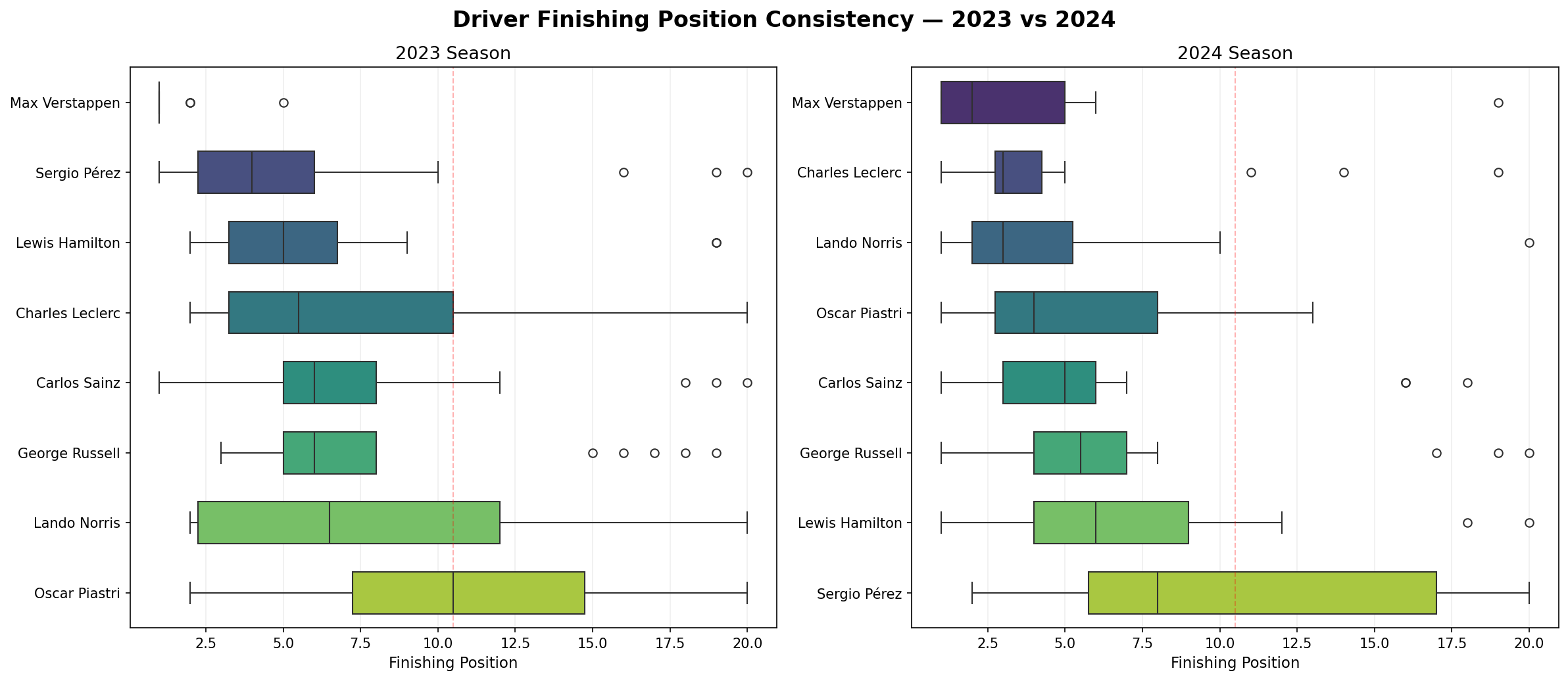
Driver Finishing Consistency
In F1 the key to winning a championship is considered to be consistency. This chart shows the spread of finishing positions for the top 8 drivers — a narrow box means reliable results, a wide box means unreliability. Verstappen's box is the tightest and leftmost in 2023, and still leftmost in 2024. Pérez's box widens dramatically in 2024. This suggests that his inconsistent driving was a big reason why Red Bull lost the constructors title.